
Abstract
Network reconfiguration is of theoretical and practical significance to guarantee safe and economical operation of distribution system. In this paper, based on all spanning trees of undirected graph, a novel genetic algorithm for electric distribution network reconfiguration is proposed. Above all, all spanning trees of simplified graph of distribution network are found. Tie branches are obtained with spanning tree subtracted from simplified graph. There is one and only one switch open on each tie branch. Decimal identity number of open switch on each tie branch is taken as the optimization variable. Therefore, the length of chromosome is very short. Each spanning tree corresponds to one subpopulation. Gene operations of each subpopulation are implemented with parallel computing method. Individuals of offspring after gene operation automatically meet with radial and connected constraints for distribution network operation. Disadvantages of conventional genetic algorithm for network reconfiguration that a large amount of unfeasible solutions are created after crossover and mutation, which result in very low searching efficiency, are completely overcome. High calculation speed and superior capability of the proposed method are validated by two test cases.
Similar content being viewed by others


Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Avoid common mistakes on your manuscript.
1 Introduction
In order to improve the reliability of power supply, urban distribution network is designed to be a looped net structure. For the sake of reducing short circuit current and facilitating protection relay settings, distribution network takes open loop operation mode. On distribution network, there are a large number of sectionalizing switches and a small amount of tie switches. By adjusting switches state, distribution network reconfiguration can reduce power loss, isolate fault, balance load, and improve voltage. At present, distribution automation demonstration projects is in full swing in many large and medium sized cities in China. Distribution automation system (DAS) can manually, interactively or automatically adjust switches state which lay a solid foundation for the application of distribution network reconfiguration.
Network reconfiguration is a large scale, nonlinear, mixed integer programming problem, mainly including branch-exchange method [1–3], optimal flow method [4, 5], genetic algorithm [6–15], heuristic method [16–18], mixed method [19], etc. Because genetic algorithm has the merits such as independency of initial values, good robustness, capabilities of finding global solutions, it attracts many scholars’ attention.
In the early genetic algorithm for network reconfiguration, binary coding scheme is widely used, in which, each gene of chromosome corresponds to one switch. If gene is 0, then it indicates switch open. While if gene is 1, it indicates switch closed. This coding scheme is easy to implement and understand. However, a large amount of switches that cannot be opened in practice participate in coding. Therefore, the chromosome is too long, and in the process of crossover and mutation, too much unfeasible solutions are brought about, which result in extremely low search efficiency.
In [7], an improved genetic algorithm for network configuration is proposed, in which, only the switches located on a loop of distribution network participate in binary coding, unfeasible solutions after crossover and mutation are ameliorated. Nevertheless, the ameliorating process is time consuming. In [8], coding genes of switches located on the same loop are in one block, and coding genes of adjacent switches adjoin are proposed. But in this method, at each generation, crossover operation can only be implemented on one gene block, and mutation operation can only be done on one gene. Furthermore, in the process of mutation, unfeasible solutions are brought about. Consequently, the search efficiency of this method is comparatively low. In [9], a decimal coding scheme that the identity number of open switch located on loop is coded with an integer is proposed. In this method, if there is not any one switch located on more than one loops, then no unfeasible solutions are produced in the process of gene operation. Unfortunately, if there is switch located on more than one loops, many unfeasible solutions are produced.
In this paper, a novel genetic algorithm based on all spanning trees of undirected graph for distribution network reconfiguration is proposed. Above all, in the graph of distribution network, branches not located on any loop are removed, and adjacent branches whose crossing points have a degree of two is incorporated into one edge. Thus, an undirected simplified graph of distribution network is obtained. All spanning trees of this simplified graph are found with a program using backtracking and a method for detecting bridges based on depth-first search. Tie branches are obtained with spanning tree subtracted from the simplified graph. There is one and only one switch open on each tie branch. Once the switch on each tie branch is open, all other switch must be closed so as to meet the radial and connected constraints for distribution network operation. Which tie branches and which switch on each tie branch is chosen to be open are determined by genetic algorithm.
In this paper, a decimal coding scheme that the whole switch number of each tie branch constitutes the base vectors, and identity number of open switch on each tie branch taken as the optimization variables are proposed. With such a coding scheme, the length of chromosome is equal to the number of independent meshes on the graph of distribution network. Therefore, it is very short. In the genetic algorithm, one sub-population corresponds to one spanning tree. Selection, crossover, mutation, reinsertion operations are all taken in sub-population with paralleling computing method. Individuals of offspring after gene operation automatically meet radial and connected constraints for distribution network operation. None unfeasible solutions are produced and none ameliorating operation is needed. The disadvantages of conventional genetic algorithm for distribution network reconfiguration that a huge number of unfeasible solutions which result in very low search efficiency brought in the process of crossover and mutation operation are completely overcome. When the specified number of evolution generation is reached, the chromosome whose objective function value is minimal in the whole population is output as the global optimal solution. Two simulation cases indicate the proposed algorithm greatly improve calculation speed.
2 Model of network reconfiguration
The objective is that power loss is minimal after network reconfiguration under necessary constraints for distribution network operation. The objective function is formulated as
where P i , Q i are active and reactive power flowing through the terminal of branch i, respectively; U i is the terminal node voltage of branch i; n is the total number of branches; \( r_{i} \) is the resistance of branch i; \( k_{i} \) is the switch state of branch i, which is a 0 or 1 discrete variable, with 0 indicating switch open, and 1 indicating switch closed; f is the active power loss of network, which can be obtained by power flow calculation.
Node voltage and branch power must meet the following constrains:
-
1)
Node voltage constraint
where \( U_{i\,\hbox{min} } \), \( U_{i\,\hbox{max} } \) are the upper and lower voltage constraints for node i, respectively.
-
2)
Branch power constraint
where \( S_{i} \), \( S_{i\,\hbox{max} } \) are the calculated and allowed maximal power value flowing through branch i respectively.
When node voltage or branch power exceeds constraint, a penalty function will be taken into account in f. The more is the constraints being exceeded, the more is penalty function.
3 All spanning trees of simplified graph and relevant concepts
3.1 All spanning trees and tie branches of simplified graph
In order to decrease the number of spanning trees and reduce calculation complexity, adjacent branches located on a loop whose crossing point have a degree of 2 are incorporated into one edge, and branches not located on any loop can be removed from the graph of distribution network. Thus, the graph of distribution network can be simplified to a graph G. Spanning tree of G is a sub-graph of G, in which, any two nodes have one and only one simple path. Spanning tree of G has all nodes of G, but do not have all edges of G. Different spanning trees are composed of different edges. Tie branches are supplementary set of spanning tree. That is, tie branches equal to spanning tree subtracted from G. The number of edges in tie branches equals to the number of independent mesh in G. In this paper, we introduce the method in [20] to find all the spanning trees and corresponding tie branches of G.
Fig. 1 is IEEE typical three feeder test system, in which, dotted line are the branches on which tie switches located. In order to facilitate finding all the spanning tree, bus 1, 2 and 3 are connected together. With adjacent branches located on a loop whose crossing point have a degree of 2 incorporated into one edge. With branches not located on any loop removed, Fig. 1 is simplified to Fig. 2. It can be seen from Fig. 2, edges ①, ③, ④, ⑤ constitute a spanning tree while edges ②, ⑥, ⑦ are the corresponding tie branches. Edges ①, ②, ④, ⑤ constitute another spanning tree while edges ③, ⑥, ⑦ are the corresponding tie branches. All spanning trees and the corresponding tie branches of Fig. 2 are listed in 2nd and 3rd column of Table 1.

IEEE typical three feeder test system

Simplified system
3.2 Base vector of tie branches
Base vector is composed of total switch number on each tie branch. Taking tie branches ①, ②, ④ for example, as shown in the second row, third column of Table 1, there is 1 switch on edge ①, 5 switches on edge ②, and 1 switch on edge ④. Thus, the base vector of this tie branches is \( \left( { 1 { 5 1}} \right) \). All the base vectors of Fig. 2 are listed in 4th column of Table 1.
3.3 Candidate solutions
Any combination of open switches that meet the radial and connected constraints for distribution network operation is defined as a candidate solution for network reconfiguration. The optimal solution can only be one of the candidate solutions. One candidate solution can be created if and only if open one switch on each tie branch. As to each spanning tree, the number of candidate solutions equals to the product of each component of the corresponding base vector. For example, shown as the 2nd row, 5th column of Table 1, number of candidate solutions corresponding to 1st spanning tree is \( 1 \times 5 \times 1 = 5 \). That is, there are 5 combinations of open switches meeting the radial, connected constraints for distribution network operation. The total number of candidate solutions of network reconfiguration equals to the sum of candidate solutions corresponding to each spanning tree. Shown as the 26th row, 5th column of Table 1, there are 190 candidate solutions for the IEEE typical 3 feeder test system.
4 Coding scheme and gene operation
4.1 Coding scheme
In this paper, decimal coding scheme is introduced. Subpopulations are one-to-one relevant to spanning trees. The length of chromosome is equal to the number of tie branches, which is equal to the number of independent meshes of distribution network. In contrast to conventional binary coding scheme, the proposed decimal coding scheme can greatly shorten the length of chromosome. The value of each gene is a non negative integer, indicating the open switch identity number on corresponding tie branch. The value of each gene is smaller than corresponding component of corresponding base vector. When we talk about a chromosome, we must point out the subpopulation it belongs to. If two chromosomes have the same genes but belong to different subpopulations, they have different meanings. For example, if chromosome \( \left( { 0 { 0 0}} \right) \) belongs to 1st subpopulation corresponding to 1st spanning tree in Table 1, it implies the 0th switch of tie branch ①, ②, ④ are open. Otherwise, if chromosome \( \left( { 0 { 0 0}} \right) \) belongs to 2nd subpopulation corresponding to 2nd spanning tree in Table 1, it implies the 0th switch of tie branch ①, ④, ⑥ are open.
4.2 Creation of initial population
Number of individuals in each subpopulation can be different according to the candidate solutions for the corresponding spanning tree. For example, because there are 15 candidate solutions correspondent to the 3rd spanning tree in Table 1, individuals number of the 3rd subpopulation can be chose to be 2. While there are 45 candidate solutions correspondent to the 10th spanning tree in Table 1, the individuals number of the 10th subpopulation can be chose to be 6.
4.3 Fitness value of chromosome
The open switches in the distribution network can be obtained by decoding the chromosome in each subpopulation. Network power loss is calculated with parallel back forward sweep power flow calculation method introduced in [21]. Power losses, with their corresponding chromosomes are sorted in ascending order. Order numbers in descending order are uniformly spaced mapped to real numbers 0~2. That is, the fitness value of chromosome with biggest power loss is mapped to 0, while the fitness value of chromosomes with smallest power loss is mapped to 2. The intervals of fitness value between any two adjacent chromosomes after sorted are equal.
4.4 Gene operation
Gene operation includes selection, crossover, mutation, and reinsertion, all of which are implemented in each subpopulation with parallel computing. After specified number of evolution generation, the individual whose objective value is minimal in the whole population (not in subpopulation) is output as the optimal solution.
-
1)
Selection
In each subpopulation, because numbers of individuals are different, numbers of individuals selected to perform gene operation are different. Roulette method are introduced for selection.
-
2)
Crossover
Crossover is to exchange the number at the same position of parents, with a specified probability. For example, shown as Table 2, if the crossover probability is specified to 0.7, the offspring of parents chromosomes \( \left( { 4 { 2 1}} \right) \), \( \left( { 2 { 1 2}} \right) \) may be \( \left( { 2 { 1 1}} \right) \), \( \left( { 4 { 2 2}} \right) \).
-
3)
Mutation
Mutation is to replace the gene of parent with a non negative integer smaller than the corresponding component of base vector. For example, shown as Table 3, if the mutation rate is specified as 0.01, and the base vector is \( \left( { 5 { 3 3}} \right) \), the chromosomes \( \left( { 4 { 2 1}} \right) \), \( \left( { 2 { 1 2}} \right) \), after mutation may be \( \left( { 3 { 2 1}} \right) \), \( \left( { 2 { 2 2}} \right) \).
-
4)
Reinsertion
As to each subpopulation, after crossover and mutation, specified numbers of individuals whose fitness values are smallest are removed from the parents. Then, the offspring are inserted into the parents. Thus, in each subpopulation, new individuals are created while multiple old elite individuals are retained and population sizes are kept constant.
4.5 Parallel computing
Coding, creation of initial population, calculation of fitness values and gene operations are all implemented in subpopulations. There is little coupled calculation between subpopulations. Therefore, it is very suitable for parallel computing. The calculation speed is highly improved, with parallel computing.
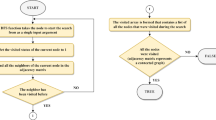
4.6 Flow chart of the proposed algorithm
The flow chart of the proposed algorithm is shown as Fig. 3. When the specified number of evolution generation is reached, the individual whose objective value is smallest in the whole population (not in the subpopulation) is output as the optimal solution of the network reconfiguration problem.

Flow chart of the algorithm
5 Simulation case
Two simulation cases are taken to test the capability of the proposed method under the condition that there is single power supply and multiple power supply. In order to facilitate recording data, the optimal solution is determined with the proposed method. Then the optimal solution is taken as the program termination condition. All the relevant programs are written by MATLAB language.
Case 1: shown as Fig. 1, there are 3 feeders, 16 nodes, 3 independent meshes in this distribution network. Fig. 2 is the simplified graph of Fig. 1. There are 24 spanning trees and total 190 candidate solutions for Fig. 2. The length of each chromosome is 3. Because the total amount of candidate solutions is very small, in each subpopulation, chromosomes are chosen to be one-to-one relevant to candidate solutions. That is, a method of exhaustion is introduced to directly find the optimal solution.
Case 2: shown as Fig. 4, there are 69 nodes, 73 branches, 5 independent meshes in this distribution network. Fig. 5 is the simplified graph of Fig. 4. There are 463 spanning trees and 377417 candidate solutions for Fig. 5. The length of each chromosome is 5. The number of subpopulations equals to that of spanning trees. In the 37 subpopulations which correspond to the most candidate solutions, there are 4 individuals for each population. While in the rest 426 subpopulations, there are 2 individuals for each subpopulation. Therefore, there are 1,000 individuals for the whole population. The crossover rate is 0.7, and the mutation rate is 0.01. The program is performed 50 times.

American PG&E 69 nodes distribution network

Simplified graph of Fig. 4
Reconfiguration results and relevant statistical data for case 1 and 2 are shown as Table 4 and Table 5.
As for the 16 nodes system, it takes 0.012 s to find the optimal solution. As for 69 nodes system, it takes 6.22 times of average evolution generation and 0.534 s to find the optimal solution, much better than the results of [8]. The reason why the reconfiguration results of the proposed method are different from that of [8] is that because there are no loads at nodes 45, 46, 47, open switches on the branches 44-45, 45-46, 46-47, 47-48 have the same effect.
It can be seen from the cases that the proposed method has very high search efficiency and calculation speed.
6 Conclusions
In this paper, a genetic algorithm based on all spanning trees of simplified graph of distribution network for network reconfiguration is proposed. The total candidate solutions and their distribution can be precisely calculated, which can supply information for determining the numbers of subpopulations and individuals in each subpopulation. The disadvantages of conventional genetic algorithm for distribution network reconfiguration that a large amount of unfeasible solutions are created in the process of crossover and mutation is completely overcome. Therefore, search efficiency of the proposed algorithm is highly improved. The identity number of open switch on each tie branch is taken as the optimization variable and decimal coding scheme is introduced. As a consequence, the length of chromosome is greatly shortened and storage space is minimized while calculation speed is improved. There is little calculation coupled between subpopulations. So it is very suitable for parallel computing. Two cases indicate that the proposed algorithm has the merits of high calculation speed and superior capabilities.
References
He YQ, Peng JC, Wen M et al (2010) Minus feasible analysis unit and fast algorithm for distribution network reconfiguration. P CSEE 30(31):50–56 (in Chinese)
Civanlar S, Grainger JJ, Yin H et al (1988) Distribution feeder reconfiguration for loss reduction. IEEE Trans Power Deliv 3(3):1217–1223
Bi PX, Liu J, Zhang WY (2001) A refined branch-exchange algorithm for distribution networks reconfiguration. P CSEE 21(8):98–103 (in Chinese)
Lei JS, Deng YM, Zhang BM (2001) Hybrid flow pattern and its application in network reconfiguration. P CSEE 21(1):57–62 (in Chinese)
Liu W, Han ZX (2004) Distribution network reconfiguration based on optimal flow pattern algorithm and genetic algorithm. Power Syst Technol 28(19):29–33 (in Chinese)
Liu J, Bi PX, Dong HP (2002) Simplified analysis and optimization of complicated distribution network. China Electric Power Press, Beijing, China (in Chinese)
Bi PX, Liu J, Zhang WY (2001) Study on algorithms of distribution network reconfiguration. Autot Electr Power Syst 25(14):54–60 (in Chinese)
Li XM, Huang YH, Yin XG (2004) Genetic algorithm based on improvement strategy for power distribution network reconfiguration. P CSEE 24(2):49–54 (in Chinese)
Bi PX, Liu J, Liu CX et al (2002) Refined genetic algorithm for power distribution network reconfiguration. Autom Electr Power Syst 26(2):57–61 (in Chinese)
Ma XF, Zhang LZ (2004) Distribution network reconfiguration based on genetic algorithm using decimal encoding. Trans China Electrotech Soc 19(10):65–69 (in Chinese)
Nara K, Shiose A, Kitagawa M et al (1992) Implementation of genetic algorithm for distribution system loss minimum re-configuration. IEEE Trans Power Syst 7(3):1044–1051
Xu K (2008) Study on network reconfiguration based on improved adaptive genetic algorithms. Master Thesis, Guangxi University, Nanning, China (in Chinese)
Wang YS, Chen GM, Zhang JS et al (2006) Optimal switching device placement based on niche genetic algorithm in distribution networks. Trans China Electrotech Soc 21(5):82–86 (in Chinese)
Liu L, Cheng XY (2000) Reconfiguration of distribution network based on fuzzy genetic algorithms. P CSEE 20(2):66–69 (in Chinese)
Yu YX, Duan G (2000) Shortest path algorithm and genetic algorithm based distribution system reconfiguration. P CSEE 20(9):44–49 (in Chinese)
Ge SY, Liu ZF, Yu YX (2004) An improved Tabu search for reconfiguration of distribution systems. Power Syst Technol 28(23):22–26 (in Chinese)
Wang SX, Wang CS (2000) A novel network reconfiguration algorithm implicitly including parallel searching for large-scale unbalanced distribution systems. Autom Electr Power Syst 24(19):34–38 (in Chinese)
Taleski R, Rajicid D (1997) Distribution network reconfiguration for energy loss reduction. IEEE Trans Power Syst 12(1):398–406
Chen GJ, Li JG, Tang GQ (2002) Tabu search approach to distribution network reconfiguration for loss reduction. P CSEE 22(10):28–33 (in Chinese)
Gabow HN, Myers EW (1978) Finding all spanning trees of directed and undirected graphs. SIAM J Comput 7(3):280–287
Yan W, Liu F, Wang GJ et al (2003) Layer-by-layer back/forward sweep method for radial distribution load flow. P CSEE 23(8):76–80 (in Chinese)
Author information
Authors and Affiliations
Corresponding author
Additional information
CrossCheck date: 29 April 2014
Rights and permissions
This article is published under license to BioMed Central Ltd. Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article

Cite this article
ZHANG, J., YUAN, X. & YUAN, Y. A novel genetic algorithm based on all spanning trees of undirected graph for distribution network reconfiguration. J. Mod. Power Syst. Clean Energy 2, 143–149 (2014). https://doi.org/10.1007/s40565-014-0056-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40565-014-0056-0